


Security Weekly 16-21/2/25 - Black Basta chat leak
Questa settimana la dedico interamente all'analisi del leak di BlackBasta ransomware chat log: indagine tecnica

Buon sabato e ben ritrovato caro cyber User.
In questa puntata:
IL CASO: Il gruppo ransomware BlackBasta subisce una esfiltrazione da un insider
L’analisi: vediamo come ho approcciato la grande quantità di dati
Dal JSON ai CSV leggibili
Utenti univoci
Distribuzione oraria delle chat
Distribuzione mensile delle chat
IOCs
Chat Rooms
BlackBasta leak: un insider diffonde chat interne al gruppo criminale
Recentemente, un utente di Telegram noto come "ExploitWhispers" ha pubblicato online centinaia di migliaia di messaggi interni del gruppo ransomware Black Basta. Questo leak ha suscitato grande interesse tra gli esperti di sicurezza informatica, che stanno lavorando per tradurre e analizzare i dati in russo.
Le chat rivelano una forte instabilità all'interno del gruppo, causata principalmente da conflitti interni guidati da figure chiave come "Tramp", un noto attore malevolo legato alla rete Qbot. Alcuni membri sono stati accusati di aver truffato le vittime riscuotendo pagamenti senza fornire decryptor funzionanti.
Tra le altre informazioni emerse, si segnala l'adozione da parte degli affiliati della tecnica della doppia estorsione e l'uso intensivo dei servizi VPN per ottenere accessi non autorizzati. Inoltre, il gruppo mantiene una lista mirata delle potenziali vittime e ha adottato tecniche social engineering simili a quelle utilizzate dal gruppo Scattered Spider.
Queste rivelazioni offrono preziose informazioni sulla struttura e sulle tattiche operative del gruppo Black Basta, che è stato particolarmente attivo nel colpire aziende in diversi settori globalmente.
L’analisi: il mio approccio ai dati
Ho deciso di dedicare questa puntata di NINAsec unicamente a questo tema, per entrare nello specifico su come potersi ricavare strumenti utili fai-da-te per incentivare i dettagli durante una indagine di threat intelligence, come può essere quella offerta da questo leak.
Il leak è costituito da un file JSON di 48 MB, con dentro oltre 1.900.000 righe di testo. Una mole così importante di dati, deve essere indagata e per farlo si deve ricorrere a qualche strumento matematico che ci possa aiutare. In questa dashboard (che ho creato con Tableau con il materiale che vedremo qui), si può notare come una mole così grande di dati, può raccontarci qualcosa di dettagliato e tracciare un profilo, guidato dai dati.
Iniziamo con il conteggio degli utenti
Quindi cosa ho fatto? Ho usato un po’ di Python per convertire l’enorme JSON in piccoli pezzi CSV con dentro dati aggregati e comprensibili, poi facilmente navigabili con strumenti come Excel (se volete) oppure Tableau (come nel mio caso).

Per prima cosa mi sono occupato di raggruppare gli utenti, che nel JSON sono identificati con “sender_alias”, e memorizzarne le occorrenze di ciascuno: in questo modo capiamo chi sono gli utenti più partecipanti alla chat e più attivi.
Per fare questo il codice Python utile è questo:
import json
import os
import pandas as pd
from collections import defaultdict
# Percorsi ai file JSON
file_paths = [
"bestflowers.json"
]
# Funzione per contare le occorrenze di ogni sender_alias nei file
def count_sender_occurrences(file_paths, sender_key):
sender_counts = defaultdict(int)
for file_path in file_paths:
with open(file_path, "r", encoding="utf-8") as file:
try:
content = file.read()
# Conta le occorrenze dei sender_alias
lines = content.split("\n")
for line in lines:
if sender_key in line:
parts = line.split(sender_key)
if len(parts) > 1:
sender = parts[1].split(",")[0].strip().strip(":").strip('"')
sender_counts[sender] += 1
except Exception as e:
print(f"Errore nella lettura di {file_path}: {e}")
return sender_counts
# Conta le occorrenze dei sender_alias
sender_alias_counts = count_sender_occurrences(file_paths, "sender_alias")
# Ordina i risultati per numero di occorrenze (dal più alto al più basso)
sorted_sender_alias_counts = sorted(sender_alias_counts.items(), key=lambda x: x[1], reverse=True)
# Salva la lista completa degli utenti con il numero di messaggi in un file CSV
# Creazione del dataframe
df_senders = pd.DataFrame(sorted_sender_alias_counts, columns=["Sender Alias", "Numero di Messaggi"])
# Salvataggio in un file CSV
csv_path = "sender_alias_counts.csv"
df_senders.to_csv(csv_path, index=False, encoding="utf-8")
csv_pathA questo punto se tutto ha funzionato correttamente, abbiamo ottenuto il primo CSV per la nostra idagine sul JSON gigante.
Passiamo al conteggio dei messaggi nelle ore
Ora continuiamo la nostra indagine cercando di capire le usanze del gruppo, proviamo analizzando le ore più attive della chat. Per farlo ho raggruppato il campo “timestamp” (come si può vedere dallo screen del JSON che ho allegato in alto), nelle 24 ore del giorno dalla 0 alla 23esima ora. Abbiamo così una distribuzione mediana di messaggi nelle ore del giorno.
Il codice Python per fare questo è il seguente
from collections import Counter
import re
file_paths = [
"bestflowers.json"
]
# Dizionario per contare i timestamp per ogni ora del giorno
hourly_counts = Counter()
# Espressione regolare per catturare le ore nei timestamp (formato "YYYY-MM-DD HH:MM:SS")
timestamp_pattern = re.compile(r"\d{4}-\d{2}-\d{2} (\d{2}):\d{2}:\d{2}")
# Scansione dei file per estrarre le ore
for file_path in file_paths:
with open(file_path, "r", encoding="utf-8") as file:
try:
content = file.read()
matches = timestamp_pattern.findall(content)
for hour in matches:
hourly_counts[int(hour)] += 1 # Converte in intero per l'ordinamento
except Exception as e:
print(f"Errore nella lettura di {file_path}: {e}")
# Creazione della tabella con le ore 0-23 (anche se assenti)
hourly_data = [(hour, hourly_counts.get(hour, 0)) for hour in range(24)]
# Creazione del DataFrame e salvataggio CSV
df_hours = pd.DataFrame(hourly_data, columns=["Ora", "Numero di Messaggi"])
csv_hourly_path = "hourly_message_counts.csv"
df_hours.to_csv(csv_hourly_path, index=False, encoding="utf-8")
csv_hourly_pathDa qui si ottiene qualcosa di questo tipo (se visualizzato su grafico)
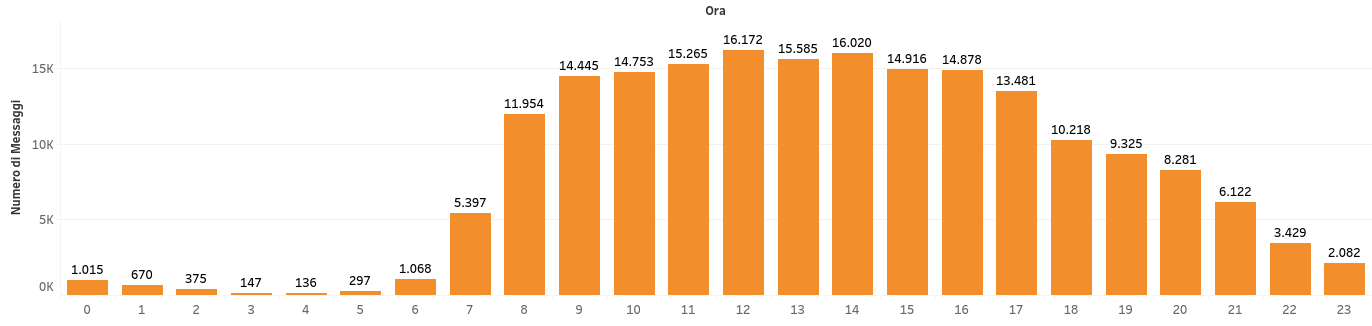
Poi la distribuzione nei mesi
Dall’analisi del campo “timestamp” era emerso in diverse notizie che il leak avrebbe contenuto un periodo di conversazioni che parte da settembre 2023 a settembre 2024.
Ora sarebbe utile capire quali sono stati i periodi di maggior attività del gruppo BlackBasta e come evolve questo andamento durante l’anno.
Anche per questo, ricorriamo ad uno piccolo script Python
from datetime import datetime
file_paths = [
"bestflowers.json"
]
# Dizionario per contare i timestamp per ogni mese
monthly_counts = Counter()
# Espressione regolare per catturare i mesi nei timestamp (formato "YYYY-MM-DD HH:MM:SS")
month_pattern = re.compile(r"(\d{4}-\d{2})-\d{2} \d{2}:\d{2}:\d{2}")
# Scansione dei file per estrarre i mesi
for file_path in file_paths:
with open(file_path, "r", encoding="utf-8") as file:
try:
content = file.read()
matches = month_pattern.findall(content)
for month in matches:
monthly_counts[month] += 1
except Exception as e:
print(f"Errore nella lettura di {file_path}: {e}")
# Conversione delle date in formato leggibile (es. "Settembre 2023")
month_names = {str(i).zfill(2): name for i, name in enumerate(
["Gennaio", "Febbraio", "Marzo", "Aprile", "Maggio", "Giugno",
"Luglio", "Agosto", "Settembre", "Ottobre", "Novembre", "Dicembre"], start=1)}
# Creazione della tabella formattata
monthly_data = [(f"{month_names[month.split('-')[1]]} {month.split('-')[0]}", monthly_counts[month]) for month in sorted(monthly_counts)]
# Creazione del DataFrame e salvataggio CSV
df_months = pd.DataFrame(monthly_data, columns=["Mese", "Numero di Messaggi"])
csv_monthly_path = "monthly_message_counts.csv"
df_months.to_csv(csv_monthly_path, index=False, encoding="utf-8")
csv_monthly_pathAnche qui, visualizzando con un dataviz qualsiasi, si ottiene una immagine chiara dei momenti gloriosi e di decadimento del gruppo ransomware.

Vogliamo ora estrarre gli Indici di Compromissione (IoC) che troviamo dentro il JSON? Bene, in questo caso ho fatto largo uso delle regular expressions, per trovare domini, IP, password e nomi di file.
Possiamo utilizzare questo codice Python
import json
import os
import re
file_paths = [
"bestflowers.json"
]
# Espressioni regolari per estrarre IOC
ip_pattern = re.compile(r"\b(?:\d{1,3}\.){3}\d{1,3}\b") # Indirizzi IP
domain_pattern = re.compile(r"\b(?:[a-zA-Z0-9-]+\.)+[a-zA-Z]{2,}\b") # Domini
credential_pattern = re.compile(r"\b(?:Login|User|Username|Pass|Password|Pwd):\s*([\S]+)", re.IGNORECASE) # Credenziali
filename_pattern = re.compile(r"\b[\w\-. ]+\.(exe|dll|zip|rar|7z|tar|gz|dat|vbs|sh|bat|ps1|txt|docx|pdf|csv|xls|xlsx)\b", re.IGNORECASE) # Nomi di file
# Dizionari per memorizzare gli IOC unici
ioc_data = {
"IP Addresses": set(),
"Domains": set(),
"Credentials": set(),
"Filenames": set()
}
# Analisi dei file
for file_path in file_paths:
with open(file_path, "r", encoding="utf-8") as file:
try:
content = file.read()
# Estrazione IOC
ioc_data["IP Addresses"].update(ip_pattern.findall(content))
ioc_data["Domains"].update(domain_pattern.findall(content))
ioc_data["Credentials"].update(credential_pattern.findall(content))
ioc_data["Filenames"].update(filename_pattern.findall(content))
except Exception as e:
print(f"Errore nella lettura di {file_path}: {e}")
# Creazione del DataFrame con IOC organizzati
max_len = max(len(ioc_data["IP Addresses"]), len(ioc_data["Domains"]), len(ioc_data["Credentials"]), len(ioc_data["Filenames"]))
# Creazione di un dizionario strutturato per il DataFrame
structured_ioc_data = {
"IP Addresses": list(ioc_data["IP Addresses"]) + [""] * (max_len - len(ioc_data["IP Addresses"])),
"Domains": list(ioc_data["Domains"]) + [""] * (max_len - len(ioc_data["Domains"])),
"Credentials": list(ioc_data["Credentials"]) + [""] * (max_len - len(ioc_data["Credentials"])),
"Filenames": list(ioc_data["Filenames"]) + [""] * (max_len - len(ioc_data["Filenames"])),
}
# Creazione DataFrame e salvataggio CSV
df_iocs = pd.DataFrame(structured_ioc_data)
csv_ioc_path = "ioc_list.csv"
df_iocs.to_csv(csv_ioc_path, index=False, encoding="utf-8")
csv_ioc_pathPer individuare l’elenco delle chat rooms utilizzate nell’arco dell’anno con un CSV che elenchi il corrispondente numero di messaggi all’interno di ciascuna chat, ho utilizzato il medesimo codice Python rappresentato sopra nel passaggio relativo agli utenti unici.
Infine contanto le righe di ciascuna raccolta, abbiamo anche un motore di statistiche generali.

Raccolti tutti i materiali della nostra indagine, si possono assemblare per rendere i numeri visualizzabili e navigabili. Come detto io ho usato Tableau, entrando nella dashboard puoi navigare i singoli grafici e ottenere il dettaglio delle quantità per ciascuno, entrando anche nel dettaglio di ciascuna voce.
Per ora il viaggio dentro Python e dentro il leak di BlackBasta, e delle loro fila criminali, è terminato. Ora se questo esperimento di visualizzazione dei dati vi è piaciuto, tocca a voi sperimentare, con questi o altri strumenti. Condividete!
A questo proposito colgo l’occasione per ribadire che di questi ed altri argomenti, si parla anche nella nuova community di Ransomfeed che ho aperto questa settimana: il forum.
Anche quest'oggi abbiamo concluso, ti ringrazio per il tempo e l'attenzione che mi hai dedicato, augurandoti buon fine settimana, ti rimando al mio blog e alla prossima settimana per un nuovo appuntamento con NINAsec.
Il network
Con questo piccolo schema riepilogo in breve i punti di riferimento che alimento con i miei contenuti, su diversi fronti, quasi quotidianamente.
Ransomfeed.it - piattaforma di monitoraggio ransomware, realtime;
inSicurezzaDigitale.com - blog di sicurezza informatica con approfondimenti tematici;
SecureBulletin.com - news internazionali su cyber security, analisi e frodi;
Spcnet.it - notizie geek;
ilGlobale.it - note politiche e di economia, di rilevanza internazionale;
Ziobudda.org - notizie Linux, open source e software libero, segnalabili e commentabili (socialnews).
NewsDF - il raccoglitore di tutto questo, con un suo feed RSS generale, per non perdere niente di quello che pubblico.